Fallstudie: Einsatz der bedeutungsorientierten
Suchmaschine SEMPRIA-Search als firmenweite
Suche in einer Beratungsfirma
SEMPRIA GmbH
Grafenberger Allee 277–287
40237 Düsseldorf
https://www.sempria.de/
info@sempria.de
Letzte Überarbeitung: 2025-11-14
Inhaltsverzeichnis
1 Vorbemerkungen
Für die vorliegende Fallstudie wurde die Konzipierung, Implementierung und fortlaufende
Evaluierung der bedeutungsorientierten Suchmaschine SEMPRIA-Search in einem
mittelständischen Beratungsunternehmen mit über 100 Mitarbeitern ausgewertet. Zur
Einfachheit wird diese Firma der Fallstudie im Folgenden IT42consult genannt. Die
Fallstudie sollte untersuchen, welche Vorteile und Potentiale eine tiefe semantische (also:
bedeutungsorientierte) Suche als firmenweite Suchmaschine (Enterprise Search Engine)
bietet.
1.1 Definition der firmenweiten Suche
Bei einer firmenweiten Suche (Enterprise Search) sollen möglichst alle relevanten Dokumente
eines Unternehmens oder einer Organisation als Volltexte durchsuchbar sein. Wichtige
Metadaten wie Schreibdatum, Titel, Bereiche, Rechte u.v.m sind einzubeziehen. Zu
den Dokumentenquellen gehören Dateisysteme, Microsoft SharePoints, Mailserver,
Contentmanagement-Systeme (CMS), Dokumentenmanagement-Systeme (DMS), Wikis und
externe Websites.
1.2 Einsatz von KI
Wir setzen seit über 20 Jahren Methoden der künstlichen Intelligenz (KI, AI) ein. Unsere
KI-Komponenten bewähren sich mit Menschen-lesbaren Repräsentationen und sprachlichen
Konzepten im Zentrum. Dieser Ansatz ist bekannt als symbolische KI (oder auch konzeptuelle
KI oder repräsentationelle KI). Die symbolische KI unterscheidet sich in Vorteilen und
Nachteilen deutlich von der generativen KI (GenAI). Treffer und Inferenzen sind stets belegbar
und erklärbar; Halluzinationen, Falschinformationen und Lügen wie bei LLMs können so
vermieden werden. Andererseits leistet die symbolische KI bisher nur recht wenige
Inferenzschritte (z.B. wie Export und Import semantisch zusammenhängen), was aber für eine
bessere Suche schon einen großen Unterschied macht. GenAI kann auf Kundenwunsch in die
Suchlösung integriert werden, zum Beispiel durch Retrieval-Augmented Generation (RAG). Für
die Suche im Unternehmen ist eine solid gescheite Suchmaschine oft die passende
Wahl.
2 Herausforderungen und Anforderungen für eine firmenweite Suche
2.1 Vielzahl von Quellen
In Firmen trifft man meist auf eine Mischung von folgenden Dokumentenquellen:
-
Microsoft SharePoint, auch mehrere SharePoints
-
Intranet
-
Dateisysteme
-
Mails
-
Contentmanagement-Systeme (CMS)
-
Dokumentenmanagement-Systeme (DMS)
-
Wikis und
-
Websites (eigene und fremde)
Im Unternehmen der Fallstudie wurde in mehreren Gesprächsrunden mit den technischen und
fachlichen Ansprechpartnern folgende Quellen identifiziert:
-
2 große SharePoints mit circa 200.000 Dokumenten
-
mehrere Dateisysteme von Windows Server mit circa 400.000 Dokumenten
-
3 externe Websites (von nationalen und internationalen Branchenorganisationen
bzw. Regulatoren) mit circa 6.000 Dokumenten
2.2 Formate: aller Art und aus allen Zeiten
Mit den Quellen ändern sich auch die Formate. Es treten Office-Formate wie DOCX, PPTX
und XLSX auf, aber auch alte Schätze als RTF. Und natürlich Unmengen an PDFs. Für jedes
Format muss die genaue Extraktion des Textes programmiert werden. Und zwar am besten in
der logischen Lesereihenfolge, was bei vielen PDFs angesichts von mehreren Spalten und
Fußnoten gar nicht einfach ist.
2.3 Metadaten-Vielfalt
Die Website-Suche kann oft einen umfassenden Satz an Metadaten (Autor, Schreibdatum,
Änderungsdatum, Stichwörter etc.) aus dem CMS übernehmen. Bei Enterprise-Search muss für
jedes Quellsystem eine Übernahme in ein harmonisiertes Metadaten-Schema der
Suchmaschine programmiert werden. Und manchmal ist es genauer oder verlässlicher, ein
Metadatum wie Schreibdatum aus dem Namen oder Anfang des Dokuments zu
extrahieren.
Für die IT42consult war die geographische Einschränkung der Suche (z.B. nach Bundesland
des Auftraggebers) eine Anforderung, die aus dem Feedback der ersten 12 Monate entstand.
Dazu wurde eine bestehende Datenbank der Firma geeignet exportiert, so dass jedes
Projekt und damit jedes Dokument einen Ort (und damit ein Bundesland) zugewiesen
bekommt.
Die Metadaten erlauben eine mächtige Einschränkung von Suchtreffern mittels der
sogenannten facettierten Suche. Nach einer initialen Suche wird angezeigt, dass z.B. die
Treffer nach den Jahr (2024, 2025) und den Dokumententyp (PDF, XLSX) eingeschränkt
werden können.
Im Gespräch mit den Nutzer:innen in der Fallstudie wurden die wichtigsten Facetten
ausgewählt und nach Wichtigkeit in der Suchmaske angeordnet. Um das Interface nicht zu
überlasten, wurden einige Spezialfälle ausgeblendet. Diese Entscheidungen wurden zur
jährlichen Überprüfung hinterlegt.
Die Suchergebnisseiten (SERPs) sollten die Metadaten der Treffer lesbar und übersichtlich
präsentieren. In der IT42consult wurden einige wenige Metadaten-Attribute ausgeblendet, um
ausreichend viele Suchtreffer auf einer Monitor-Seite sehen zu können. Weitere Details können
zum Beispiel beim Bewegen des Mauszeigers (mouse-over) in bestimmte Regionen
eingeblendet werden.
2.4 Textdokumente: auch ohne Text?
Oft kommt folgende Ernüchterung nach Einführung einer internen Suchmaschine auf: Wir
haben doch dieses tolle PDF, in dem alles steht, aber es wird nie gefunden. Dann stellt sich
schnell heraus, dass viele PDFs (und andere Dateiformate) gar keinen Text für die eigene
Suchmaschine liefern können, da sie nur Rastergrafiken aus einem Scanner oder Fotoapparat
sind. Eine gute kognitive Enterprise-Search schaltet dort eine optische Zeichenerkennung
(OCR) vor, so dass auch diese Dokumente inhaltlich erschlossen werden können.
Manchmal lohnt es sich sehr, die OCR für die Besonderheiten der Dokumente zu
trainieren.
Bei der IT42consult stellte sich heraus, dass ein beträchtlicher Teil der gescannten PDFs
schon ein OCR-Ergebnis (von über 20 verschiedenen Programmen) enthielt. Eine Evaluation
zeigte, dass in der Mehrzahl der Fälle ein aktuelles OCR-Programm deutlich bessere Ergebnisse
liefert. Daher wird bei jedem gescannten PDF mit enthaltenem OCR-Ergebnis ein
neues OCR-Ergebnis produziert und das beste Ergebnis der beiden für die Suche
indexiert.
2.5 Multimedia: schön, aber ohne Worte
Video-Dateien und Audio-Dateien enthalten oft wichtige Informationen, aber meist ohne Text.
Analog zu OCR bei Scans ist hier Spracherkennung (ASR) einzusetzen, um Texte
hinzuzufügen, die man per Suchanfrage in Textform finden kann.
In der Dokumenten-Welt der IT42consult spielen Audios und Videos keine Rolle, so dass
diese von der Indexierung ausgeschlossen wurden.
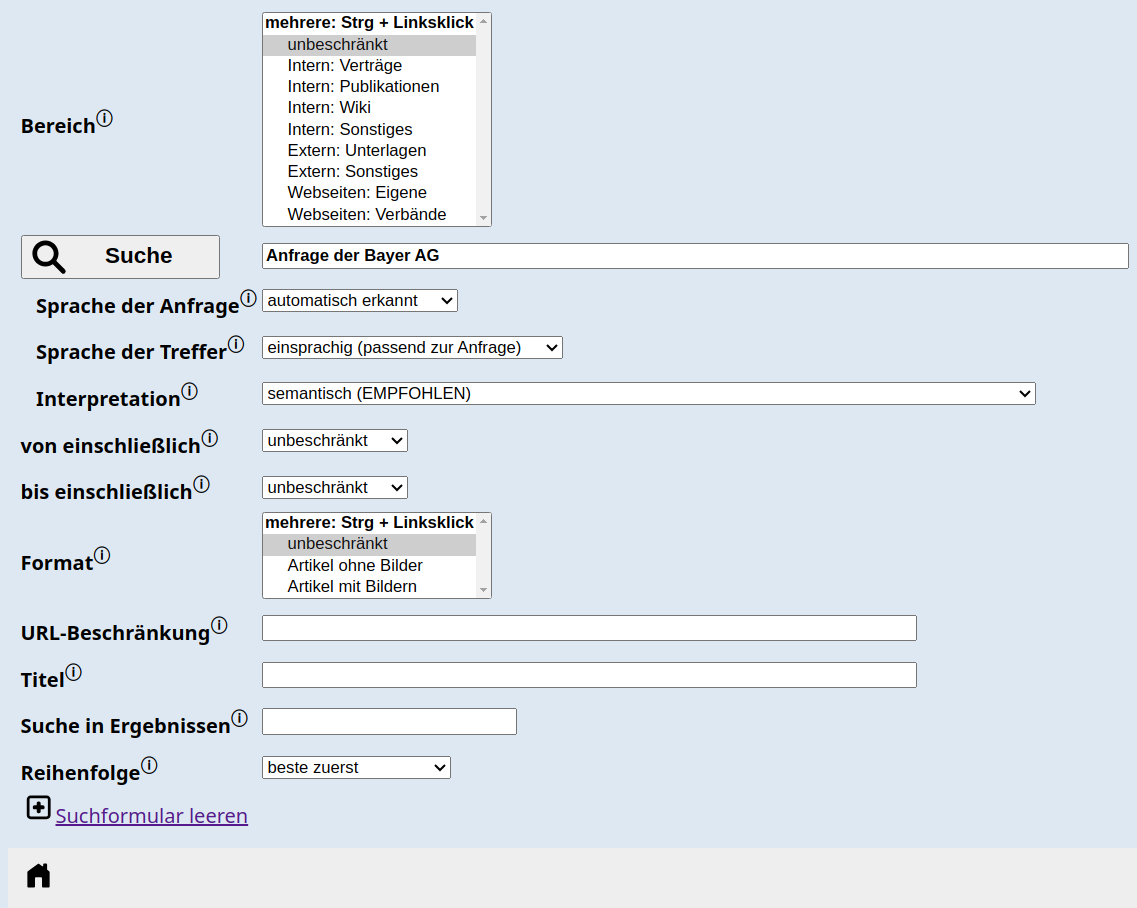
2.6 Graphisches Nutzer-Interface (GUI)
Bei Website-Suche kommt man oft mit einem minimalen Suchschlitz von 20 Zeichen aus.
Ganz anders bei Enterprise-Suchmaschinen. Hier hat man viel mehr Metadaten und
Informationen zu den Quellen und Quellsystemen. Schnell ist ein gesamter Bildschirm gefüllt
mit einer Suchmaske (s. Abbildung 1), ggf. mit Untermasken. Für die Power-Nutzerschaft ist
das natürlich ein mächtiges Tool, aber für Otto-Normal-Suchende ist es angemessener,
zusätzlich ein vereinfachtes Such-Interface anzubieten, das nur die wichtigsten Auswahlen bei
Metadaten und Facetten beinhaltet.
2.7 Leserechte und Zugriffsrechte: wer darf was?
Viele Quellen, die in eine Enterprise-Search eingehen, haben ein ausgeklügeltes Rechtesystem
(ActiveDirectory, LDAP etc.). Aus Suchmaschinensicht interessiert besonders, wer darf
welche Dokumente lesen? Dies muss durch die Enterprise-Search genau nachgebildet
werden.
In der IT42consult wird ActiveDirectory intensiv eingesetzt, mit Hunderten von (teilweise
technisch bedingten) Gruppen. Ähnliches gilt für die SharePoints. Die Rechte aus
den Quellsystemen werden auf die Dokumentenrechte der indexierten Dokumente
projiziert.
2.8 Babylon: mehrsprachig statt einsprachig
Viele Website-Suchmaschinen sind einsprachig, da nur deutsche Dokumente vorhanden sind.
Im Enterprise-Umfeld ist Mehrsprachigkeit der Standard. Besonders deutsche und englische
Dokumente sollen gefunden werden, egal ob man auf Englisch oder Deutsch Suchanfragen
formuliert.
In der IT42consult zeigte die automatische Sprachidentifikation für alle Dokumente, dass
Deutsch etwa 80 % und Englisch etwa 20 % ausmacht. Die mehrsprachige Suche hat hier also
eine starke Berechtigung.
2.9 Duplikate: … und noch eine Kopie … und nochmal als PDF
Bei Website-Suche sind Duplikate eher selten; in Enterprise-Suchmaschinen sehen wir hingegen
Duplikatsquoten von 20 % bis 75 %. Ohne eine Duplikatserkennung bedeutet dies bei einer
Duplikatsquote von beispielsweise 75 %, dass im Schnitt 3 von 4 Dokumenten in
Treffern redundant sind. Die Lesezeit und Recherchezeit können sich also unnötig
vervierfachen!
Duplikate sind nicht einfach nur Byte-identische Dokumente, sondern man sollte sie auch über
Formatgrenzen hinweg erkennen, z.B. wenn ein PDF aus einem DOCX oder XLSX generiert
wurde. Welches Format in den Treffern bevorzugt angezeigt wird, ist Teil der Konfiguration
oder Personalisierung der internen Suchmaschine.
Für die IT42consult beträgt die Duplikatsquote 24 %. Eine besondere weitere
Herausforderung war, dass die Suchmaschine nur ein Dokument pro Duplikatsgruppe als
Treffer zeigen soll, aber gleichzeitig kompakt alle Duplikate auch verfügbar machen
soll. Dies ist besonders wichtig, wenn die Zugriffsrechte in einer Duplikatsgruppe
manuell nicht konsistent vergeben wurden; ein Fall, der häufiger war, als von allen
erwartet.
2.10 Datenschutz und DSGVO
Firmenweite Suchmaschinen werden oft als Cloud-Lösung im Ausland (USA u.a.) angeboten.
Weitere Möglichkeiten sind der Betrieb in einem ausländischen Rechenzentrum,
in einem inländischen Rechenzentrum oder in der Firma selbst als Server-Lösung
(on-premises).
Für die IT42consult spielt Datenschutz eine große Rolle. Prinzipiell sollen keine Daten die
Firma verlassen, so dass die Server-Lösung (on-premises) ideal war. Da die Suchmaschine keine
Software oder Dienste von Dritten verwendet, sind die Daten genauso gut geschützt wie die
bestehenden Daten der Firma. Technisch läuft die Suchmaschine in einem Linux einer
Virtuellen Maschine auf einem bereits bestehenden und noch nicht ausgelasteten Server.
Hardwarekosten konnten so vermieden werden. Eine sichere Fernwartung konnte nach dem
Stand der Technik umgesetzt werden.
2.11 Nutzer-definierte Dokumenten-Kollektionen
Viele Nutzer:innen haben den Wunsch, eigene Dokumenten-Kollektionen zu definieren, z.B.
durch die einfache Zuweisung eines sogenannten Tags zu den Dokumenten einer Trefferseite
(SERP). Diese Kollektionen können dann als Einschränkung in der Suche verwendet
werden.
Für die IT42consult waren Dokumenten-Kollektionen eine Grundanforderung. Zusätzlich war
wichtig, dass man private und öffentliche Tags unterscheiden kann. Ein öffentliches Tag ist für
die Nutzerschaft der Suchmaschine sichtbar und kooperativ pflegbar.
2.12 Domänenwissen
Für viele Firmen lohnt es sich, bestehendes formalisiertes Wissen (wie Thesauren) in die Suche
zu integrieren.
Für die IT42consult galt das besonders für die komplizierten Teil-Ganzes-Beziehungen
zwischen kleineren Firmen und Mutterkonzern und offizielle, inoffizielle und abgekürzte
Schreibvarianten von Firmennamen und Einrichtungsnamen. In der Branche gibt es weiterhin
viele spezifische Abkürzungen, die teils für andere Begriffe stehen als in anderen Branchen.
Zum Beispiel kann DB für Datenbank, für Dezibel, für eine Großbank, für einen Bahnkonzern
u.a. stehen. Dieses Domänenwissen wurden mit geringem Arbeitsaufwand in die firmenweite
Suchmaschine integriert.
2.13 Externe Datenquellen
Die Integration von Wikipedia (Wikidata, Wikivoyage u.ä.) ist für einige Institutionen ein
lohnendes Unterfangen, sofern eine gute Ergänzung der Institutions-eigenen Dokumentenbasis
möglich ist.
Für die IT42consult mit ihrer sehr speziellen Domäne wurden keine großen Vorteile erwartet,
so dass keine externen Datenquellen (wie für andere Firmen erfolgreich umgesetzt) indexiert
wurden.
2.14 Integrierte Texttechnologie-Funktionen
Wenn man mit viel Aufwand für die firmenweite Suche möglichst umfassend die
Dokumente einer Organisation erschlossen hat, dann bietet es sich an zu überlegen,
was man für diesen Dokumenten-Schatz sonst noch Sinnvolles machen kann. Als
Ideen und Bausteine sind einige populäre Texttechnologie-Funktionen zu nennen:
-
automatische Verschlagwortung und Verstichwortung, Facetten
-
Lesbarkeitsbeurteilung für Texte
-
Auffinden von Wiederholungen und Plagiaten (auf semantischer Ebene, nicht nur
auf Zeichenebene)
-
Auffinden von Widersprüchen
-
Infoboxen, Linkboxen, Themenseiten und Specials
-
automatische Zusammenfassung (Abstracting)
-
semantische Versionsanalyse von Texten
-
Überprüfung von Terminologien (Organisations-weite Schreibungen und
Fachbegriffe)
3 Qualitätssteigerung der Treffer durch kognitive bedeutungsorientierte Suche
SEMPRIA-Search verfolgt einen kognitiven bedeutungsorientierten Ansatz, d.h. alle
Dokumente und alle Suchanfragen werden in formale Bedeutungsrepräsentationen übersetzt.
Diese können in Repräsentationen für synonyme oder ähnliche Formulierungen umgeformt
werden; auch Inferenzen arbeiten auf diese Weise. Der Vorteil dieser repräsentationellen KI
ist, dass alle Treffer erklärt werden können. Die Suchmaschine bringt durch dieses
repräsentationelle Sprachverstehen viele unterschiedliche (aber gleichbedeutende)
Formulierungen zwischen Suchanfrage und Dokumententext zusammen (dadurch höhere
Vollständigkeit der Suche). Andererseits vermeidet sie falsche Übereinstimmungen (dadurch
höhere Genauigkeit der Suche).
Die IT42consult entschied erst einmal, dass keine Erklärungen eingeblendet werden sollen,
um das Interface der Suchmaschine nicht zu überfrachten. Eine Überprüfung wurde für die
vereinbarten jährlichen Statusgespräche angesetzt.
Um einen Eindruck von der Art und Vielfalt der behandelten Sprachphänomene
bezüglich Synonymie, Ähnlichkeit und Inferenz zu bekommen, folgen nun einige wichtige
Phänomen-Klassen.
-
Erweiterte Suche mit Synonymen (Dentallabor - Zahnlabor)
-
Erweiterte Suche durch Begriffshierarchien, also Verbindungen zwischen
Unterbegriffen und Oberbegriffen (Neodym ist eine Seltene Erde)
-
Nutzung von Namensvarianten (Venetien - Venezien - Veneto)
-
Erweiterte Suche mit alternativen Formulierungen (Export - ausführen)
-
Komposita und deren Umschreibungen (feinsandiger Strand - Feinsandstrand)
-
Ausnutzung von geographischem Wissen (Amberg liegt in Bayern)
-
Behandlung von Mehrdeutigkeiten (Der Jaguar fuhr einen altersschwachen Jaguar
an.)
-
Vergleich von Bedeutungen, kein Vergleich von Zeichenketten (Das BMI berichtet
über den steigenden BMI.)
-
Querbezüge im Text (Fr. Klein - die Beraterin - sie)
-
Multilinguale interne Suchmaschine (Sessel - armchair; Fernverkehr -
long-distance traffic)
-
Fragefunktion (Wer exportiert Uran?)
-
Verschiedene Orthographien vom 18. Jahrhundert bis heute (aufwendig -
aufwändig)
-
Robustheit gegen Schreibfehler (Terasse - Terrasse; Fussball - Fußball)
4 Evaluation
Da die Suchmaschinen-Installation der Fallstudie noch recht jung ist, liegen noch nicht alle
Evaluationsdaten vor.
Der Erfolg und die gesteigerte Qualität gegenüber der Vorgänger-Lösung (Standardsuche des
SharePoints) lässt sich am besten an der Zahl der Nutzer:innen und der Zahl der
Suchanfragen ablesen. Bei gleichbleibender Zahl an Mitarbeitern der Firma stieg die Zahl der
aktiven Nutzer:innen schrittweise von 10 % auf circa 50 %. Dies ist ein sehr guter
Prozentsatz, da zur Mitarbeiterschaft auch Externe zählen, die aus technischen und
organisatorischen Gründen die firmenweite Suche gar nicht nutzen sollen. Die IT42consult
bot gelegentlich einen halbstündigen Workshop zum Thema Recherche im Hause
an, um den erfolgreichen Einsatz der neuen Suchmaschine voranzubringen. Noch
stärker als die Nutzerzahlen stiegen die Suchzahlen an und zwar um einen Faktor
8.
Wichtig für die Steigerung dieser beiden Zahlen war, dass das Feedback (wie Vorschläge von
neuen Features, Sonderwünsche, Fehlermeldungen) in der IT42consult gesammelt wurde und
der Hersteller der Suchmaschine möglichst agil Verbesserungen zu den wichtigsten
Feedback-Themen einer Testnutzergruppe in der Firma anbieten konnte. Bei Erfolg wurden
diese Anpassungen dann firmenweit freigeschaltet.
5 Nächste Schritte
Die Autor:innen dieser Fallstudie sind für Fragen unter der Mail-Adresse info@sempria.de und
telefonisch unter 0211 566693-57 zu erreichen. Einmalige und fortlaufende Kosten können
nach Bestimmung einiger weniger Parameter zuverlässig kalkuliert werden.
Testsysteme sind möglich und oft zu empfehlen. Die Kosten eines Testsystems (ohne
Sonderwünsche und ohne größere Anpassungen) werden dem Interessenten nicht berechnet.
Wie in der IT42consult ist als Dokumentengrundlage für ein Testsystem eine repräsentative
Stichprobe von 2 % bis 10 % des Dokumentenbestands zu empfehlen.